
Кризис поисковых систем
Можно перечислить ряд проблем, с которыми столкнулись современные поисковые системы в Интернете. Например, разрастание общего объема материалов, расположенных в Интернете, переход к новым форматам (XML); увеличение количества нетекстовых материалов (MP3, RealVideo и т.д. ). Конечно, каждая из этих проблем очень серьезна, в этих направлениях ведутся достаточно продуктивные работы, обсуждению результатов которых можно посвятить не одну главу обзорных статей. Здесь мы постараемся коснуться основной, как кажется, проблемы, с которой встретились современные поисковые системы (ПС), присутствующие на современном рынке средств текстового поиска (намеренно избегаем термина информационно-поисковые системы — ИПС, почему, будет объяснено ниже). Проявилась эта проблема при наращивании объема индексируемых текстовых документов. Такой рост объема текстов, помещенных в поисковую систему (проиндексированных поисковой системой) привел к тому, что практически любой запрос выдает выборку из многих тысяч, а то и десятков тысяч подходящих документов. Естественно, это превышает максимум, который способен обработать один человек за разумное время. Такой максимум для профессионального аналитика находится в пределах нескольких сотен документов, для непрофессионала, естественно, границы существенно ниже, как минимум, на порядок. Итак, эта проблема – избытка информации.
Проблема эта не является новой, для решения ее и создавалась технология ПС. Но на сегодняшнем этапе эта технология не может адекватно справиться с соответствующими задачами. Пользователю безразлично, что утонуть в океане миллиарда документов, доступных ему во всем Интернете, что захлебнуться в озере сотни тысяч документов, заботливо и бесплатно отобранных по его запросу ПС. Проблема усугубляется тем, что выросло количество пользователей Интернет, не обладающих профессиональными навыками в поиске информации при использовании возможностей языка запросов. Конечно, эта проблема коснулась не только ПС, занимающихся индексированием материалов в Интернете, но и ПС, работающих с любыми другими текстовыми базами (электронными библиотеками — ЭБ). К таким системам относятся известные библиотеки НЭБ-НСН, Интегрум-Техно в России, Лексис-Нексис, Рейтер на Западе. Пользователей у таких ПС, естественно, существенно меньше, чем у ПС в Интернете, хотя объем документов, доступных в ПС Лексис-Нексис, не только существенно выше объема Интернет, но даже скорость поступления новых документов в эту библиотеку до сих пор превосходит скорость поступления в Интернет. Однако, даже гораздо более строгая организация данных в таких библиотеках, полное единство форматов (или почти полное) внутри одной библиотеки, не являются панацеей от общей проблемы современных ПС. Так же точно пользователи этих ПС часто получают многие тысячи документов в ответ на свои запросы. Конечно, приведенный пример — лишь наиболее чувствительный, известный практически всем пользователям Интернет болезненный признак кризисной проблемы современных ПС. Таких признаков, как и у всякого кризиса, предостаточно.
Например, косвенное признание его наличия в сопроводительных руководствах к современным ПС. Понятно, нельзя рассчитывать на прямое признание этого факта на сайтах ПС в Интернете. Но в рекомендациях для пользователей на таких сайтах содержатся подтверждения непростоты поиска информации при помощи ПС. Даже говорится о том, что «поиск — это искусство» [1]. Ясно, что в области искусства нельзя добиться гарантированного, а тем более массового результата. Еще одним кризисным признаком является увеличение популярности (заслуженное, на фоне беспомощности ПС) каталогов типа YAHOO!.. Метод рубрицирования, используемый такими каталогами, обладает рядом существенных недостатков, по сравнению с ПС, однако эти недостатки становятся менее значимыми по сравнению с основной проблемой современных ПС. Наконец, наличие этого кризиса признают современные ученые и обозреватели рынка ПС. Так, о непреодолимом младенчестве нынешнего поколения ПС говорит Аманда Спинк из университета штата Пенсильвания [2]. Обозреватель PCWorld Брайан МакВильямс пишет о том, что поиск в Интернете бесполезен [3]. Нельзя не сказать о путях, приведших к этому кризису. Есть впечатление, что сложность построения реальных больших ПС (объемом в миллионы текстовых документов) с одной стороны, дала представление о трудностях дальнейшего их развития, а с другой, создала иллюзию достаточности такого инструмента для решения всех задач поиска. Некоторые методы построения таких ПС изложены Храмцовым П.С. (РНЦ «Курчатовский институт») [4].
Стандартные методы технологии ПС и их модификации
Теперь пора сказать о привычном термине информационно-поисковая система (ИПС). Реально нынешние системы ищут информацию лишь в виде документов, так что точнее их можно назвать документно-поисковыми системами (ДПС).
Чаще всего ПС дают пользователю возможность поиска по заданным им «ключевым» словам. Часто для непрофессионалов есть опция поиска без употребления языка запросов. Иногда ПС позволяет задавать фразы на естественном языке. Последнее, в принципе, сводится к предыдущему, поскольку чаще всего из «естественного» запроса просто удаляются «неключевые» слова (слова из стоп-словаря). Другие системы идут по пути совершенствования языка запросов, распознавания полезных конструкций внутри текстов, например конструкций даты (отождествляя 10.12.99 или 10 декабря 1999г.).
Кроме того, некоторые системы дают пользователю возможность еще при запросе «расширить» совокупность заданных им слов. Такие системы используют лексико-семантические сети, состоящие из слов и выражений естественного языка. Такие сети могут быть построены из заранее определенных тезаурусов – система Экскалибур [5], или из анализа частотного соседства слов по всей базе – система NeurOK Semantic Server [6]. Такое расширение может происходить автоматически, невидимо для пользователя [6]. А может система и предложить такие слова из сети на выбор пользователя – система Текст-Аналист [7]. Такие методы анализа будем называть априорными (абсолютными), поскольку они накладывают заданные пользователем слова на подготовленную заранее сеть, в которой не учитывается нужная пользователю предметная область. Попытка построить относительный метод анализа текстовых документов будет изложена ниже.
Далее ПС осуществляют поиск среди документов базы, содержащих заданные слова. Внутри найденной выборки такие системы часто пытаются расположить документы в порядке их «релевантности», то есть в порядке близости к введенному пользователем запросу. Критериев такой близости довольно много [4], лучшие из них выделить непросто, да это и не является нашей задачей. Легко видеть, что выявление таких близких «по смыслу» к запросу документов не решает проблемы получения информации при отсутствии релевантного документа. Ситуация с отсутствием такого документа достаточно частая, поскольку пользователь часто ищет документ, который он сам собирается написать. Пример: некоему менеджеру предстоит командировка в регион, о котором он почти ничего не знает. Естественно, что ему нужно познакомиться с проблемами данного региона, причем текущими. Даже, если допустить, что есть обзор этого региона по интересующей менеджера тематике, то, почти наверное, в этом обзоре не отражены последние события.
Но так ли безнадежна ситуация? Означает ли отсутствие такого документа отсутствие информации, нужной пользователю? Нет, такая информация есть, только она присутствует микроскопическими дозами во многих документах базы. Нужно собрать эту рассеянную информацию и предоставить ее пользователю в концентрированном и некотором достаточно понятном виде. Чтобы понять пути решения сформулированных проблем, попробуем вернуться от рассмотрения конкретных поисковых технологий к началу. Что происходит, когда пользователь садится за клавиатуру и пытается что-то найти в очередной ПС.
Прямая и обратная задачи поиска
Пусть пользователь сидит перед мордочкой некоей ПС, сегодня это почти наверное браузер с HTML-страничкой.
При этом у пользователя есть в голове некоторая тема, которую он пытается сформулировать в виде набора ключевых слов в окошке запроса. В этом процессе пользователю можно и нужно помогать, как это делают некоторые системы [7], но основную работу пользователь, естественно, должен проделать самостоятельно.
После набора ключевых слов пользователь нажимает кнопку «искать» и дальнейшую работу ПС проводит самостоятельно. В результате получается выборка документов, которую можно рассматривать как проекцию запроса, заданного пользователем или как проекцию темы, находившейся в голове у пользователя на документы базы, находящейся под управлением данной ПС. Эта проекция зависит от технологических методов, используемых данной системой, а также от объема текстовых документов, находящихся в данной базе.
Итак, у нас получилась формулировка прямой задачи поиска:
Проецирование темы пользователя на пространство текстовых документов базы.
Ее нетрудно проиллюстрировать в виде простой схемы.
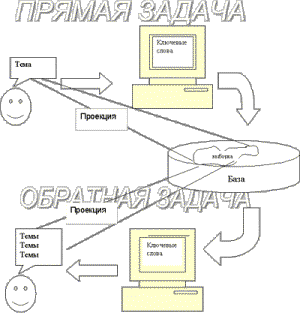
Теперь достаточно просто сформулировать обратную задачу поиска:
Проецирование выборки текстовых документов базы на пространство тем.
Для построения возможного решения обратной задачи воспользуемся этой же схемой. Только направление получаемой проекции будет теперь в обратную сторону: от базы к пользователю. Пусть пользователь получил некоторую выборку среди документов базы. Критерий этой выборки сейчас нам неважен, это может быть проекция темы, полученная в результате выполнения прямой задачи или просто отобранные вручную документы. Допустим, что у нас есть инструмент, позволяющий получить значимые «ключевые» слова и выражения данной выборки. Такой процесс наша гипотетическая ПС должна выполнять достаточно быстро «в реальном времени». Тогда, просмотрев эти слова и выражения, пользователь сможет понять темы, присущие данной выборке документов. По этим темам пользователь сможет уточнить свой запрос, выбрав близкие к нужной ему теме слова из реально присутствующих в документах. Далее можно повторить весь процесс с выполнением уточненного запроса и получением ключевых слов и выражений новой выборки. Таким образом, используя изложенную методику, можно реализовать эффективную обратную связь. Остается сделать небольшое усилие и определить критерии оценки значимости слов и выражений в выборке текстовых документов базы.
Критерий определения значимости слов в выборке документов
Понятно, что непротиворечивых критериев можно построить достаточно много. Основные требования к такому критерию – релевантность (если выборка документов получена по обычному запросу, то совокупность значимых слов должна быть «релевантна» этому запросу); реализуемость на современной технике – как сейчас принято говорить, приемлемое соотношение скорость-качество. Как обычно бывает, эти два требования выполнить одновременно непросто.
РЕКЛАМНЫЙ БЛОК
[ Хотите знать больше о частной разведке? Регистрируйтесь и общайтесь на интернет-форуме it2b-forum.ru ]В данной статье будет предложен критерий значимости слов, удовлетворяющий изложенным требованиям в допустимых пределах. Подход к построению такого критерия основан на нескольких очевидных соображениях.
Первое: тема, о которой говорят все, обычно малоинтересна – эффект «секрета Полишинеля». Следовательно, для выводов о значимости темы для выборки текстовых документов нужно оценить, как эта тема отражена в контексте данной выборки. Таким контекстом может выступать выборка существенно большего объема, например, вся база.
Второе: оценить значимость темы для пользователя по одному документу практически невозможно, требуется привлечение дополнительного материала. Это соответствует правилу «скажи мне, кто твой друг…».
Следовательно, чем больше документов найдено в ответ на запрос, тем лучше. Тем точнее можно оценить значимость темы для пользователя, «релевантность» этой темы. Таким образом, ситуация с избыточностью информации снова встает с головы на ноги. Богатство и полнота текстовой базы перестают быть недостатком, с которым надо бороться разбиением на жесткие рубрики и выделением основы документа – реферированием.
Критерием, отвечающим высказанным соображениям могло бы быть отношение относительных частот встречаемости слова в выборке и всей базе. Точнее превышение таким отношением некоторого порога. Но, к сожалению, такой простой и понятный критерий не является устойчивым в случае малых частот. Это с очевидностью следует из того, что слово, встречающееся 999 раз в выборке из 1000 во всей базе, вообще говоря, более значимо, чем слово, встретившееся в базе только 1 раз именно в этой выборке.
Исходя из вышеизложенного, более удачным критерием будет вероятность выполнения нулевой гипотезы. Нулевая гипотеза [9]состоит в том, что слово в нашей базе распределено абсолютно равномерно. Превышение же частоты встречаемости данного слова в нашей выборке происходит абсолютно случайно. Тогда мы можем посчитать вероятность выполнения такого исхода. Более подробно описание данного критерия приведено ниже.
Заключение
Вышеизложенные алгоритмы послужили одной из основ созданной поисковой технологии, на базе которой была построена система поиска и анализа «Галактика-Зум». Вот один из примеров использования данной системы на реальной текстовой базе. База – средств массовой информации (газеты, журналы) за 4 квартал 1998 года, всего более 250 источников, более 110 тысяч документов.
Таблица значимости словосочетаний
База: СМИ 98 октябрь—декабрь
Количество документов в базе: 116776
Запрос: водка
Количество документов: 2854
Количество значимых словосочетаний: 493
| Словосочетание | Коэффициент значимости | Словосочетание | Коэффициент значимости |
| ПОДАКЦИЗНЫЙ ТОВАР | 1567.0 | ПИЩЕВАЯ ПРОДУКЦИЯ | 56.4 |
| АЛКОГОЛЬНАЯ ПРОДУКЦИЯ | 793.7 | ЦЕНТРАЛЬНЫЙ РЫНОК | 52.7 |
| ЭТИЛОВЫЙ СПИРТ | 542.4 | МАЛАЯ ПОРЦИЯ | 50.3 |
| АКЦИЗНЫЙ СБОР | 305.5 | ПЕРВИЧНАЯ РЕАЛИЗАЦИЯ | 49.8 |
| ДАВАЛЬЧЕСКОЕ СЫРЬЕ | 237.9 | ОТЧЕТНЫЙ МЕСЯЦ | 49.6 |
| АКЦИЗНАЯ МАРКА | 166.5 | ПОДДЕЛЬНАЯ ВОДКА | 49.4 |
| НАСТОЯЩАЯ ИНСТРУКЦИЯ | 158.9 | АНАЛОГИЧНЫЙ ТОВАР | 49.3 |
| ПИЩЕВОЕ СЫРЬЕ | 147.9 | ЭТОТ СПИРТ | 48.6 |
| АЛКОГОЛЬНЫЙ НАПИТОК | 137.9 | КАЧЕСТВЕННАЯ ВОДКА | 48.4 |
| ЛЕВАЯ ВОДКА | 134.2 | КУРСКИЙ ВОКЗАЛ | 45.3 |
| ГОСУДАРСТВЕННАЯ МОНОПОЛИЯ | 133.5 | КРЕПКОЕ СПИРТНОЕ | 44.9 |
| ПОДАКЦИЗНЫЙ ВИД | 123.7 | МАКСИМАЛЬНАЯ ОТПУСКНАЯ | 44.2 |
| ТАБАЧНОЕ ИЗДЕЛИЕ | 103.3 | ЭТА ВОДКА | 43.5 |
| АЛКОГОЛЬНЫЙ РЫНОК | 94.8 | КРЕПКИЙ НАПИТОК | 42.5 |
| ФАЛЬШИВАЯ ВОДКА | 91.6 | СПИРТОВОЙ ЗАВОД | 41.8 |
| НАЛОГОВЫЙ ОРГАН | 84.6 | БЕЛОРУССКИЙ РЫНОК | 41.6 |
| ДЕНАТУРИРОВАННЫЙ СПИРТ | 84.1 | КАЖДАЯ БУТЫЛКА | 41.4 |
| ИДЕНТИФИКАЦИОННАЯ МАРКА | 81.1 | ЮВЕЛИРНОЕ ИЗДЕЛИЕ | 41.3 |
| ГАЗОВЫЙ КОНДЕНСАТ | 79.2 | НАТУРАЛЬНАЯ ОПЛАТА | 40.7 |
| ГОСУДАРСТВЕННОЕ РЕГУЛИРОВАНИЕ | 79.0 | ЛЕГАЛЬНОЕ ПРОИЗВОДСТВО | 40.4 |
| МИНЕРАЛЬНОЕ СЫРЬЕ | 77.1 | ЗЕЛЕНЫЙ ЗМИЙ | 39.2 |
| ЛИКЕРО-ВОДОЧНЫЙ ЗАВОД | 72.6 | ФАКТИЧЕСКОЕ ПОСТУПЛЕНИЕ | 38.7 |
| НЕЛЕГАЛЬНЫЙ ПРОИЗВОДИТЕЛЬ | 72.1 | ВОДОЧНЫЙ ЗАВОД | 38.3 |
| НАЛОГОВЫЙ РАСЧЕТ | 68.6 | ПОДПОЛЬНАЯ ВОДКА | 36.9 |
| ОТЧЕТНЫЙ ПЕРИОД | 64.6 | ЗАКОННЫЙ ОБОРОТ | 36.6 |
| НЕЛЕГАЛЬНАЯ ВОДКА | 64.1 | ГАРАНТИЙНОЕ ОБЯЗАТЕЛЬСТВО | 36.5 |
| ТАМОЖЕННОЕ ПРОСТРАНСТВО | 64.0 | ЛЕВЫЙ ТОВАР | 36.4 |
| ЯЛТИНСКИЙ ЛУК | 62.8 | ПОДАКЦИЗНАЯ ПРОДУКЦИЯ | 36.0 |
| НАЛОГОВАЯ ПОЛИЦИЯ | 60.6 | ЕГО ПРОИЗВОДСТВО | 36.0 |
| ТЕХНИЧЕСКИЙ СПИРТ | 59.3 | ВИННЫЙ НАПИТОК | 35.9 |
| ПОДПОЛЬНЫЙ ЦЕХ | 59.1 | ТАМОЖЕННЫЙ ОРГАН | 35.1 |
| НАЛОГОВАЯ ИНСПЕКЦИЯ | 57.6 | ГОРЯЧИТЕЛЬНЫЙ НАПИТОК | 34.6 |
| ДЕШЕВАЯ ВОДКА | 56.5 | АВАНСОВЫЙ ПЛАТЕЖ | 34.4 |
Из таблицы приведены словосочетания, имеющие коэффициенты значимости, соответствующие вероятности отбрасывания нулевой гипотезы в 10 девяток после нуля и выше. Обратите внимание на количество документов, на основании которых была получена данная таблица. Ясно, что вручную обработать такое количество документов не представляется возможным. Напомним, что критерий значимости – вероятность выполнения нулевой гипотезы, точнее, ее логарифм с обратным знаком. Из таблицы видно, что критерий вполне работоспособен. Практически все выведенные словосочетания имеют отношение к заданной теме.
Литература
- Как искать в Яndex? www.yandex.ru
- In Search of Right Engine. PcWorld Online. pcworld.com, 29.10.1999
- Web Searching a Lost Cause. PcWorld Online. pcworld.com 6.04.1999
- Храмцов П. «Моделирование и анализ работы поисковых систем». «Открытые системы» 1996, № 6.
- www.vest.msk.ru
- www.neurok.ru
- www.analyst.ru
- Солтон Дж. «Динамические библиотечно-информационные системы». Мир, Москва, 1979.
- Гнеденко Б.В. «Курс теории вероятностей». Наука, Москва, 1988.
По вопросам приобретения системы обращайтесь в компанию Р-Техно
Автор: Антонов А.В., Мешков В.С.
Источник: Корпорация «Галактика»



